FromNand2Tetris
A course in which you build a computer (hardware and software) from scratch.
Overview
In this famous course (often regarded as one of the best courses ever designed for Computer Science), we build a computer from scratch, and then, using a higher-level programming language that we design ourselves, develop a program that runs on that very computer.
This means that we go through all the building blocks a modern computer needs to be able to run software. In the first we design the hardware, and in the second part we focus on the software.
Part I
Part I consists of six projects:
- Boolean functions and gate logic
- Boolean Arithmetic and the ALU (Arithmetic Logic Unit)
- The main memory unit, RAM (random access memory)
- Assembly programs in the Hack assembly language
- The CPU (central processing unit), and the entire computer architecture
- The assembler for the Hack assembly language
Feel free to check out my repo for the course.
Project 1
I really enjoyed designing the chips using the HDL (Figure 1). One thing one needs to keep in mind is that the multi-bit buses are indexed from right to left, so the opposite from what one is used to. I especially enjoyed designing the Mux4Way16 and Mux8Way16, and the Dmux4Way and Dmux8Way chips. It helped to actually draw out the sketches for the designs to get a better understanding. Another interesting thing happened around this time. I saw a post by Andrej Karpathy about Cursor, a fork of VS Code, but with a built-in AI assistant (basically similar to GitHub Copilot, the only difference being that Cursor offers the chance to choose between various models, such as ChatGPT4o, Claude Sonnet 3.5, etc.). It looked pretty good and I really enjoyed using it, but it would automatically produce solutions for me for the first couple of chips. After a few minutes I realized I wasn’t solving the problems myself, and was therefore not learning anything. I deleted all the solutions and re-implemented everything myself from scratch. This could lead to a further debate on how to properly use LLMs for both work and learning, but my general feeling at the moment is simply: Don’t use them to give you solutions. Only use them as a form of quicker and more comprehensive research, or as a complement to Googling and reading the documentation. That is, if you actually want to learn anything, of course.
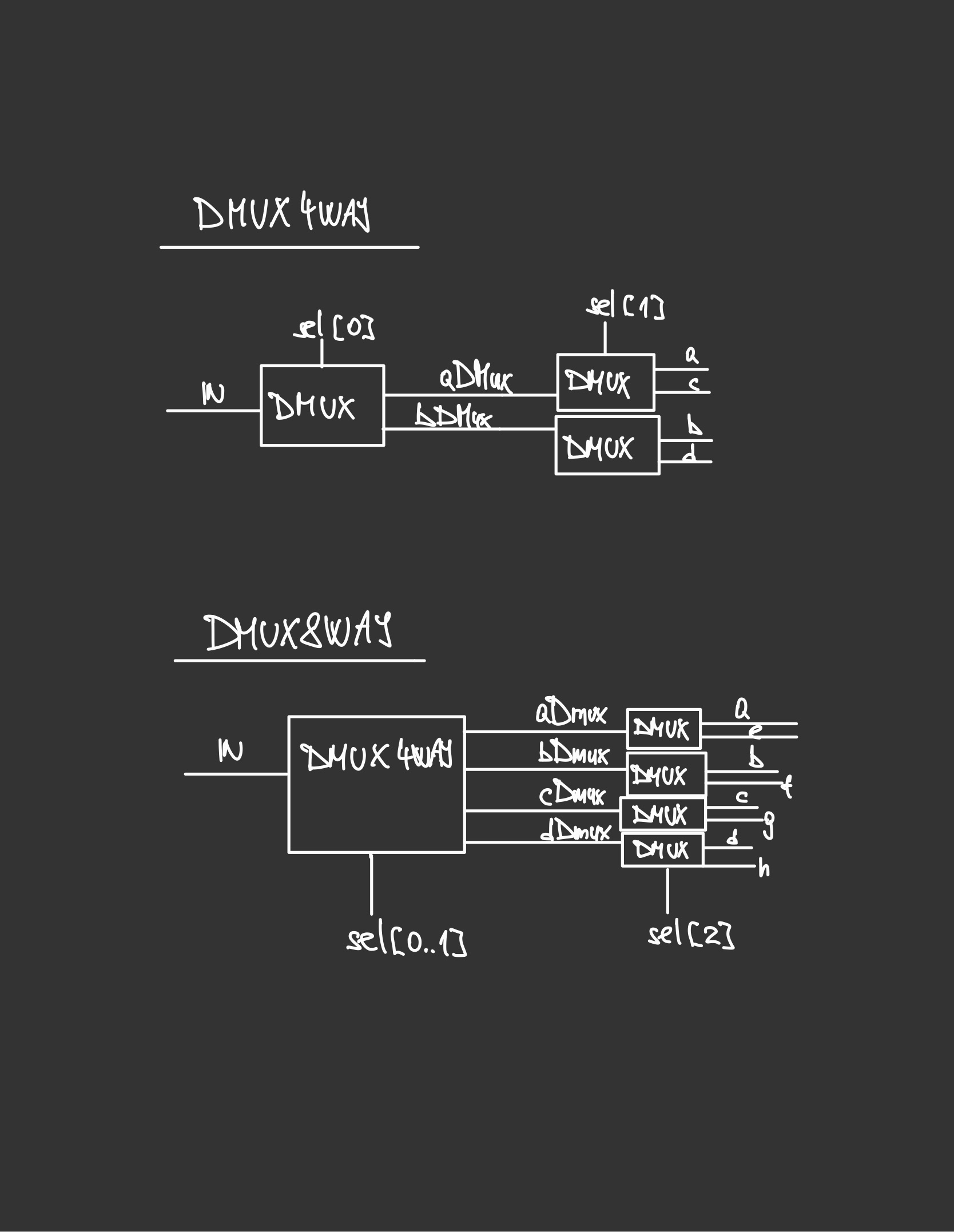 Figure 1: Design for a Dmux4Way and a Dmux8Way chip
Figure 1: Design for a Dmux4Way and a Dmux8Way chip
Project 2
In this project we built an ALU (Arithmetic Logic Unit). We built a family of adders (half-adder, full adder, add16, inc16), and then we used those to build a full ALU. The ALU computes a function on two inputs, and outputs the result. It can perform a family of 18 functions, including setting an integer to 0, negating it, addition, multiplication and division of two integers, etc. It is a simple and elegant design.
Here is my implementation in less than twenty lines of HDL code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
* ALU (Arithmetic Logic Unit):
* Computes out = one of the following functions:
* 0, 1, -1,
* x, y, !x, !y, -x, -y,
* x + 1, y + 1, x - 1, y - 1,
* x + y, x - y, y - x,
* x & y, x | y
* on the 16-bit inputs x, y,
* according to the input bits zx, nx, zy, ny, f, no.
* In addition, computes the two output bits:
* if (out == 0) zr = 1, else zr = 0
* if (out < 0) ng = 1, else ng = 0
*/
// Implementation: Manipulates the x and y inputs
// and operates on the resulting values, as follows:
// if (zx == 1) sets x = 0 // 16-bit constant
// if (nx == 1) sets x = !x // bitwise not
// if (zy == 1) sets y = 0 // 16-bit constant
// if (ny == 1) sets y = !y // bitwise not
// if (f == 1) sets out = x + y // integer 2's complement addition
// if (f == 0) sets out = x & y // bitwise and
// if (no == 1) sets out = !out // bitwise not
CHIP ALU {
IN
x[16], y[16], // 16-bit inputs
zx, // zero the x input?
nx, // negate the x input?
zy, // zero the y input?
ny, // negate the y input?
f, // compute (out = x + y) or (out = x & y)?
no; // negate the out output?
OUT
out[16], // 16-bit output
zr, // if (out == 0) equals 1, else 0
ng; // if (out < 0) equals 1, else 0
PARTS:
// Pre-setting the x-input
Mux16(a=x, b[0..15]=false, sel=zx, out=xSetZero);
Not16(in=xSetZero, out=notX);
Mux16(a=xSetZero, b=notX, sel=nx, out=xSet);
// Pre-setting the y-input
Mux16(a=y, b[0..15]=false, sel=zy, out=ySetZero);
Not16(in=ySetZero, out=notY);
Mux16(a=ySetZero, b=notY, sel=ny, out=ySet);
// Selecting between computing + or &
Add16(a=xSet, b=ySet, out=xPlusY);
And16(a=xSet, b=ySet, out=xAndY);
Mux16(a=xAndY, b=xPlusY, sel=f, out=fSet);
// Post-setting the output
Not16(in=fSet, out=notOut);
Mux16(a=fSet, b=notOut, sel=no, out=out, out[0..7]=outFirst, out[8..15]=outSecond, out[15]=outMSB);
// Setting the control bits
// Or8Way outputs 1 if any of the bits is 1, and 0 if all are 0
Or8Way(in=outFirst, out=firstPartAllZero);
Or8Way(in=outSecond, out=secondPartAllZero);
Or(a=firstPartAllZero, b=secondPartAllZero, out=allBitsZero);
Mux(a=true, b=false, sel=allBitsZero, out=zr);
// if (MSB == 1) then the number is negative
Mux(a=false, b=true, sel=outMSB, out=ng);
}
Project 3
In this part we built the computer’s main memory unit, Random Access Memory, or RAM. This marks the point where we move from combinational logic to a clock-based sequential logic. We know that the RAM is not the only type of memory in a computer. Other types are ROM (Read-only memory), which is persistent and stores the boot programs. Then we also have the cache memory (fast, small and expensive) and the disk memory (slow, large and inexpensive). The difference between RAM and cache is that cache is much faster and located closer to the CPU or even inside it, whereas RAM is located on the motherboard and is connected to the CPU via a memory bus. Cache is used for extremely fast access to data that is needed often, and RAM is used to access data and instructions that are being worked on by the system. The cache is checked first, then the RAM.
To be able to implement sequential logic, we need a gate that can “remember” the previous state. Such a gate is called a “flip-flop” gate, and in this course it was given to use. Otherwise, it can be implemented with Nand gates, by creating a “loop” and a “master-slave” setup. We used the given flip-flop gate, and other gates we built in project 1 and project 2, to build the following gates:
- Bit
- Register
- RAM8
- RAM64
- RAM512
- RAM4K
- RAM16K
- PS (Program counter)
I must admit that the program counter is the first thing in this course where I got really stuck. I could have used an LLM to help me, of course, or Googled around for tips and ideas, but I knew that the problem wasn’t that hard, and I really wanted to give my brain a proper exercise. So I tried various ways of breaking the problem down into smaller pieces, drawing diagrams, turning the concepts around in my head. In the end, I did arrive at the correct solution, and one can see the elegance of it from the diagram below (Figure 2). The logic of what input is chosen, follows the logic of what the selector bit will be in the register.
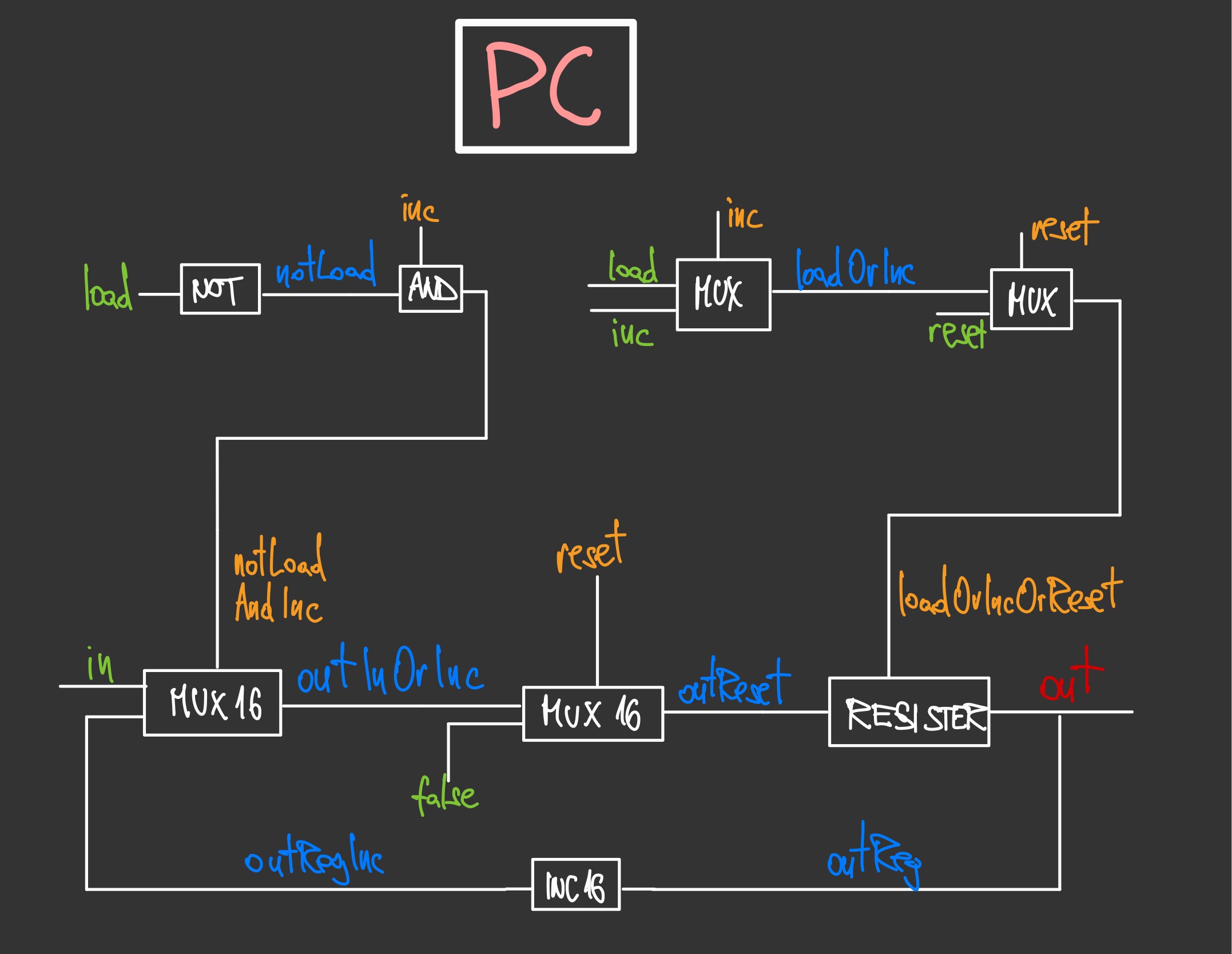 Figure 2: Design for a Program Counter (PC)
Figure 2: Design for a Program Counter (PC)
Project 4
This project was all about writing assembly programs using the Hack machine language, designed specifically for this course. I love writing low-level code, and find it intellectually much more interesting to high-level coding. The feeling of steering the computer at a very granular, basic level, gives a greater feeling of intellectual satisfaction, and reminds us of what computing is all about: zeroes and ones. It is important to note the difference between a machine language and an assembly language. The former is the zeroes and ones, the binary code that the CPU can execute. The assembly language is a level higher, a human-readable representation of machine language, which uses symbolic names (called mnemonics) instead of binary code. This makes it quite a bit easier to understand and write machine instructions. As such, there is a direct, one-to-one mapping between an assembly language and machine code, and the former is translated into the latter by an assembler.
In this project, I wrote two simple assembly programs, one that blackens the screen if any key is pressed, and whitens it if the key is released; and one that multiples two numbers. Here is the first program:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
// This file is part of www.nand2tetris.org
// and the book "The Elements of Computing Systems"
// by Nisan and Schocken, MIT Press.
// File name: projects/4/Fill.asm
// Runs an infinite loop that listens to the keyboard input.
// When a key is pressed (any key), the program blackens the screen,
// i.e. writes "black" in every pixel. When no key is pressed,
// the screen should be cleared.
//// Replace this comment with your code.
// Set the start screen address
@SCREEN
D=A
@addr
M=D
// Set the end screen address
@SCREEN
D=A
@8192
D=D+A
@endscreenaddr
M=D
(MAINLOOP)
// Listen to keyboard input
@KBD
D=M
// Blacken screen if D-reg (keyboard input) does not contain 0.
@BLACK
D;JNE
@MAINLOOP
0;JMP
// Blacken screen
(BLACK)
@addr
A=M
M=-1
@KBD
D=M
@WHITE
D;JEQ
// Check if outside of screen
// highscreenaddr = 16384 (SCREEN) + 8192 = 24576
// if (addr - 24576 = 0) => egde of screen
@addr
D=M
@24576
D=D-A
@OUTSIDESCREENHIGH
D;JEQ
// Set new address
@addr
D=M
MD=D+1
@BLACK
0;JMP
// WHITE
(WHITE)
@addr
A=M
M=0
@KBD
D=M
@BLACK
D;JNE
// Check if outside of screen
// lowscreenaddr = 16384
// if (addr - 16384 = 0) => edge of screen
@addr
D=M
@SCREEN
D=D-A
@OUTSIDESCREENLOW
D;JEQ
// Set new address
@addr
D=M
MD=D-1
@WHITE
0;JMP
(OUTSIDESCREENHIGH)
@KBD
D=M
@WHITE
D;JEQ
@OUTSIDESCREENHIGH
0;JMP
(OUTSIDESCREENLOW)
@KBD
D=M
@BLACK
D;JNE
@OUTSIDESCREENLOW
0;JMP
// Unconditional jump to start of loop
@MAINLOOP
0;JMP
Project 5
In this part we had to finish and tie together the entire computer architecture. First we build the memory module, consisting of RAM, Screen and Keyboard parts. Then we design the central processing unit (CPU), which we connect to the memory and the ROM (the module that stores whatever program we decide to run.). Naturally, the most challenging part of this project was designing the CPU. The CPU essentially performs two main tasks:
- Executes a given Hack instruction
- Determines which instruction should be fetched and executed next.
In order to achieve that, it also needs to decode the instruction, determine what type of instruction it is (in our case, either an A or a C-instruction), and route the relevant bits to the relevant parts of the architecture.
As with Project 3, the most difficult part was coming up with the logic that controls the program counter. In this case, we had to come up with a logic gate architecture that realizes the following behavior: *if jump then PC = A else PC++*.
Here is my rather simplistic implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
CHIP CPU {
IN inM[16], // M value input (M = contents of RAM[A])
instruction[16], // Instruction for execution
reset; // Signals whether to re-start the current
// program (reset==1) or continue executing
// the current program (reset==0).
OUT outM[16], // M value output
writeM, // Write to M?
addressM[15], // Address in data memory (of M)
pc[15]; // address of next instruction
PARTS:
Mux16(a=instruction, b=outALU, sel=instruction[15], out=AorCinstruction);
Mux(a=true, b=instruction[5], sel=instruction[15], out=loadAreg); // Load the A-register if the instruction is an A-instruction
ARegister(in=AorCinstruction, load=loadAreg, out[0..14]=addressM, out[0..15]=aregOut);
And(a=instruction[15], b=instruction[4], out=loadDreg); // c3 == C-instruction and d2-bit set
DRegister(in=outALU, load=loadDreg, out=dregOut);
Mux16(a=aregOut, b=inM, sel=instruction[12], out=aregOutOrInM); // Send either A-register or inM as input to the ALU
DMux8Way(in=true, sel=instruction[0..2], a=noJump, b=second, c=third, d=fourth, e=fifth, f=sixth, g=seventh, h=eight);
Not(in=noJump, out=noJumpFalse);
Not(in=zeroOut, out=notZero);
Not(in=negOut, out=notNegative);
And(a=notZero, b=notNegative, out=outGreaterThanZero);
And(a=second, b=outGreaterThanZero, out=jumpIfGreaterThanZero);
And(a=third, b=zeroOut, out=jumpIfZero);
Or(a=zeroOut, b=notNegative, out=outGreaterThanOrZero);
And(a=fourth, b=outGreaterThanOrZero, out=jumpIfGreaterThanOrZero);
And(a=fifth, b=negOut, out=jumpIfLessThanZero);
And(a=sixth, b=notZero, out=jumpIfNotZero);
Or(a=negOut, b=zeroOut, out=outLessThanOrZero);
And(a=seventh, b=outLessThanOrZero, out=jumpIfLessThanOrZero);
Or(a=jumpIfGreaterThanZero, b=jumpIfZero, out=firstOr);
Or(a=firstOr, b=jumpIfGreaterThanOrZero, out=secondOr);
Or(a=secondOr, b=jumpIfLessThanZero, out=thirdOr);
Or(a=thirdOr, b=jumpIfNotZero, out=fourthOr);
Or(a=fourthOr, b=jumpIfLessThanOrZero, out=fifthOr);
Or(a=fifthOr, b=eight, out=jumpConditions);
And(a=noJumpFalse, b=jumpConditions, out=effectJump);
And(a=effectJump, b=instruction[15], out=effectJumpIfCInstruction);
And(a=instruction[15], b=instruction[3], out=writeM); // Write to memory if d3 set and instruction is a C-instruction
PC(in=aregOut, load=effectJumpIfCInstruction, inc=true, reset=reset, out[0..14]=pc);
ALU(x=dregOut, y=aregOutOrInM, zx=instruction[11], nx=instruction[10], zy=instruction[9], ny=instruction[8], f=instruction[7], no=instruction[6], out=outM, out[0..15]=outALU, zr=zeroOut, ng=negOut);
}
The rest was quite simple, and the final Hack computer implementation can then be done in only a few lines of HDL code. Feel free to check out this part of my course repository for more detail.
Project 6
In this part we had to implement the assembler for the Hack assembly language. This was a proper, albeit small, software project, and I thoroughly enjoyed it. An assembler is, in essence, just a parsing and translation tool. I implemented the parsing without doing any rigorous validation of the instructions. This was part of the contract for the project, namely that the instructions provided would be valid. I have also, once again, pondered the value of coding with an AI assistant. As much as it might speed up the process to a certain degree, I really find it quite harmful to the learning process. I enjoy the convenience of being able to ask an LLM questions directly in the editor (I use Cursor), but I dislike the use of tab completion (except sometimes when you have to code some really tedious parts of a program). I don’t want a model to be generating code for me. I want to have an AI assistant that I can discuss the various aspects of my code with, but in the end I want the decisions and conclusions to be my own. The beauty of designing software, just like with writing a novel or a poem, is that there are many ways of doing it, and they all have their advantages and disadvantages. The important thing is that you thoroughly understand your design and its strengths and shortcomings. This becomes rather impossible with excessive use of AI assistants. And it isn’t just about the general design of code, most lines of code can be implemented in several ways. It is important to implement things in suboptimal ways also, so that you can learn and understand why they are suboptimal.
Anyway, I digress. The assembler can most certainly be improved, on both the design and practical-implementation level. But I am happy with it for now, since it simply does the job, and I have learned what I wanted to learn about assemblers. For now.
Here is my main program implementation, which follows the recommendation to pass through the program twice; in the first pass, we handle the labels, and in the second pass we handle the rest.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
namespace Assembler;
internal abstract class Program
{
private static void Main(string[] args)
{
if (args.Length == 0)
{
Console.WriteLine("Usage: Assembler <file.asm>");
return;
}
// Load the file
string file = args[0];
var parser = new Parser(file);
// The first pass (build the symbol table)
var romAddress = 0;
while (parser.HasMoreCommands())
{
parser.Advance();
if (parser.CurrentCommand == null)
{
Console.WriteLine("Current command is null.");
}
else
{
if (Parser.DetermineInstructionType(parser.CurrentCommand).Equals(InstructionType.LInstruction))
{
SymbolTable.AddEntry(
parser.Symbol() ?? throw new InvalidOperationException("Symbol cannot be null."), romAddress);
}
if (Parser.DetermineInstructionType(parser.CurrentCommand).Equals(InstructionType.AInstruction) ||
Parser.DetermineInstructionType(parser.CurrentCommand).Equals(InstructionType.CInstruction))
{
romAddress++;
}
}
}
// The second pass (translate A-instructions and C-instructions, fetch L-instructions from the symbol table,
// and handle variables)
parser.DisposeReader();
parser = new Parser(file);
var lines = new List<string>();
var variableAddress = 16;
while (parser.HasMoreCommands())
{
parser.Advance();
if (parser.CurrentCommand == null)
{
Console.WriteLine("Current command is null.");
}
else
{
Console.WriteLine(parser.CurrentCommand + " == " + Parser.DetermineInstructionType(parser.CurrentCommand));
if (Parser.DetermineInstructionType(parser.CurrentCommand).Equals(InstructionType.CInstruction))
{
const string firstBits = "111";
string? compBits = Code.Comp(parser.Comp() ?? throw new InvalidOperationException());
string? destBits = Code.Dest(parser.Dest() ?? throw new InvalidOperationException());
string? jumpBits = Code.Jump(parser.Jump() ?? throw new InvalidOperationException());
string translation = firstBits + compBits + destBits + jumpBits;
Console.WriteLine("Machine code for C-instruction " + parser.CurrentCommand + " : " + translation);
lines.Add(translation);
}
if (Parser.DetermineInstructionType(parser.CurrentCommand).Equals(InstructionType.AInstruction))
{
try
{
var number = Convert.ToInt32(parser.Symbol());
const string firstBit = "0";
string bits = Convert.ToString(number, 2).PadLeft(15, '0');
string translation = firstBit + bits;
Console.WriteLine("Machine code for numeric A-instruction " + parser.CurrentCommand + " : " + translation);
lines.Add(translation);
}
// This means that the A-instruction is either a symbolic A-instruction or a variable
catch (FormatException)
{
string? symbol = parser.Symbol();
// The A-instruction is a symbolic A-instruction
if (symbol != null && SymbolTable.Contains(symbol))
{
int symbolValue = SymbolTable.GetAddress(symbol);
// Translate the symbol value
const string firstBit = "0";
string bits = Convert.ToString(symbolValue, 2).PadLeft(15, '0');
string translation = firstBit + bits;
Console.WriteLine("Machine code for symbolic A-instruction " + parser.CurrentCommand + " : " + translation);
lines.Add(translation);
}
else
// The A-instruction is a variable
{
string? variable = parser.Symbol();
SymbolTable.AddEntry(variable ?? throw new InvalidOperationException("Symbol cannot be null."), variableAddress);
const string firstBit = "0";
string bits = Convert.ToString(variableAddress, 2).PadLeft(15, '0');
string translation = firstBit + bits;
Console.WriteLine("Machine code for variable A-instruction " + parser.CurrentCommand + " : " + translation);
lines.Add(translation);
variableAddress++;
}
}
}
}
}
string docPath = Environment.CurrentDirectory;
string? fileNameWithoutType = file.Split('.').FirstOrDefault();
using var outputFile = new StreamWriter(Path.Combine(docPath, fileNameWithoutType + ".hack"));
foreach (string line in lines)
outputFile.WriteLine(line);
}
}
Check out my code for the HACK assembler, or my repository for this course, and thanks for reading!
Certificate
 Figure 3: Certificate for Part I of the course
Figure 3: Certificate for Part I of the course
Part II
To be continued… Please check back later for updates (probably sometime in 2026).